Hadoop MapReduce 5 Tricky Challenges and their solutions
The five key challenges of working in in Hadoop MapReduce are:
- Lack of data storage and support capabilities
- Lack of application deployment support
- Lack of analytical capabilities in database
- Issues in online processing
- Privacy and Security challenges
Download Your Free Big Data Hadoop Software Requirements Document Here
MapReduce defined
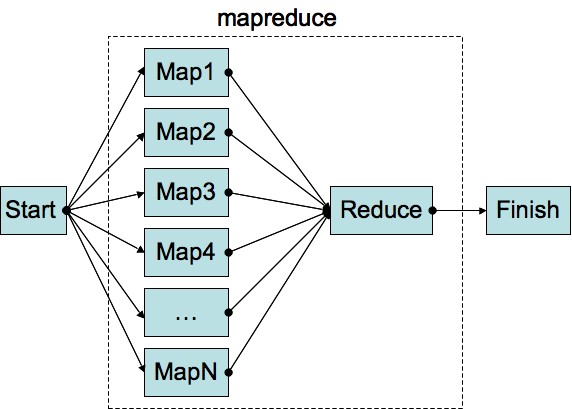
IBM defines MapReduce as two separate and distinct tasks that Hadoop programs perform.
- The first is the map job, which takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key/value pairs).
- The second is the reduce job takes the output from a map as input and combines those data tuples into a smaller set of tuples. As the sequence of the name MapReduce implies, the reduce job is always performed after the map job.
Praise be to MapReduce programming paradigm; before we explain these challenges in detail and the tools we use to workaround these challenges, let’s pen down MapReduce’s two outstanding features that set it apart from other programming models:
- Optimized distributed shuffle operation
- Fault-tolerance and minimization of redundancy
Back to the problem part.
1. Lack of data storage and support capabilities
Data storage is index- and schema-free.
Solution
The workaround is to use tools that provide in-database MapReduce processing
Tools you can use
MongoBD, Orient, HBase
2. Lack of application deployment support
There is an inherent difficulty in managing multiple application integrations on production-scale distributed system in MapReduce.
Solution
The way to go is using an enterprise-class programming model that has the ability to include workload policies, tuning, and general monitoring & administration. So, when you make an application for single function or multiple functions, you make an IPAF (Inter Protocol Acceptability Framework]
Tools you can use
Custom IPAF
3. Lack of analytical capabilities in database
Doing MapReduce functions, it is difficult to scale complex iterative algorithms. Also, there are statistical and computational challenges.
Solution
HaLoop and Twister are both extensions designed for Hadoop in order for MapReduce implementation to better support iterative algorithms. The Data pre-processing approach should be followed using MapReduce.
Tools you can use
R, MatLab, Haloop, Twister
4. Issues in online processing
Hadoop developers face performance/latency issues when doing MapReduce job. It is difficult to perform online computations with the existing programming model.
Solution
The use of other programming models (for example, MapUpdate, a new programming paradigm by Muppet Project). Using Twitter’s Storm and Yahoo’s S4, that maintains runtime platforms inspired by MapReduce implementations.
Tools you can use
Apache Storm
5. Privacy and Security challenges
There are issues in auditing, access control, authentication, authorization and privacy when performing mapper & reducer jobs.
Solution
Employ trusted third party monitoring and security analytics as well as privacy policy enforcement with security to prevent information leakage.
Tools you can use
Apache Shiro, Apache Ranger, Sentry
We’v been using these tools in our MapReduce jobs, let us know if you know of some other tools that perform better.
Related Posts
 Hadoop Foundation III: Laying the architecture & tools that compliment Hadoop
Hadoop Foundation III: Laying the architecture & tools that compliment Hadoop Hadoop Foundation II: What type of data Hadoop can help me with?
Hadoop Foundation II: What type of data Hadoop can help me with? Big Data Skills: The super-set of a Data Scientist’s skills
Big Data Skills: The super-set of a Data Scientist’s skills- Data Scientists and Justin Trudeau: 5 amazingly common things between the Canadian PM and data scientists
 Big Data – Weekly News
Big Data – Weekly News Big Data – Weekly News
Big Data – Weekly News