
Machine Learning: Different types simplified
Data Science, Artificial Intelligence, and machine learning are contributing immensely to the developments in the modern era. Machine learning to be specific is contributing a lot to several industries.
In very simple words machine learning has been defined as a “computer’s capacity to learn from experience.”
Aim of machine learning
It is to develop algorithms that are capable of learning how to perform particular tasks following an example set of data. Let us consider a few examples of machine learning in everyday life. When you browse on the internet, several use cases such as autocomplete or autocorrect become evident to the human brain. If you are looking for a movie or a program on Netflix or a YouTube video, recommendation systems are used there in the devices.
All such abovementioned applications develop with certain integration of machine learning. It is hence obvious that machine learning is excelling in several fields. There are tons of such applications relevant to machine learning in almost every major industry or company.
Types of Machine Learning (ML)
As discussed already, Machine Learning (ML) refers to algorithms used for pattern identification within a set of data. But what exactly is ML, what is all about “models” and “training” them? Let’s begin with different types of ML use cases:
Supervised Learning
This type of ML implies that we have a defined target to predict the given data set. For instance,
- Credit Card Companies figure out the credit card limit based on the customer’s profile and credit history
- Digital media companies, if customers will churn using their activities on the platform
- Automobile manufacturing companies estimating sales of their tractors following macroeconomic and weather data
- Gmail predicting about the email’s category via its sender, subject, and body
These supervised ML algorithms enable the users to predict the target (credit limit, if the customer will churn, sales of the tractor, or the email category) with the help of input data (credit history, customer activity on the platform, macroeconomic and weather conditions, email specifications).
Supervised learning has two types based on the target’s category:
- If the target is a number such as credit limit or tractor sales, the problem is termed a Regression problem
- If the target is a category, for instance, if a customer will churn – Yes or No; which folder the email belongs – Primary, Promotions, or Spam, it will be called a Classification problem
Example of use case:
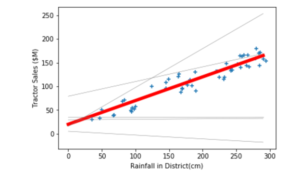
Let’s assume we are a tractor manufacturing company and we want to predict the sales of our tractors. We are aware that rainfall affects the sales of tractors. Considering last year’s data, we notice a linear regression model i.e. considering sales (target) as y and rainfall (input variable) as x, we may express the data as y = mx + c or in other words, Sales = slope * Rainfall + Intercept
We may get different lines of m and c, but we are concerned with the values giving us the line closest to the data points.
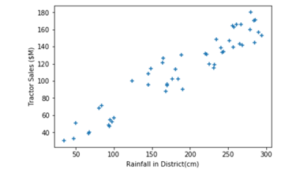
Of all the possible lines in grey, the one in bold red is closest to the required data. Using this line to estimate the sales from the rainfall, we would be able to make predictions closest to sales numbers. Therefore, if rainfall can be predicted, sales can be predicted as Sales = m* Rainfall + c
Using these values of m and c, we have our solutions. Similarly, if the Linear Regression has been fit to a straight line on the given set of data, different models will fit the functions onto our data i.e. try to find the spots closest to the data. Classification algorithms work in the same manner. The only difference is that they give us maximum accuracy to as many points as possible in the data set.
All the models such as Logistic Regression, Linear Regression, Decision Trees, SVMs, Random Forests, Deep learning models, or Neural Networks are trying to estimate the maximum accurate predictions. This process of finding the optimum values for particular functions calls it “training”.
Important things about data:
Quantity and Quality
If there are few points of data, this implies a lack of appropriate evidence, and we may not be sure of the predictions made. On the other hand, huge data also does not guarantee good predictions. If there is heavy rainfall than in history, we may not be able to predict sales accurately. This is because the model has never seen such heavy rainfall. The context is significant as well. For instance, a model trained for Pakistan may be workable for similar demographics but will be giving wrong predictions with different dynamics, like the United States.
Domain expertise
The type of the model and its implementation are part and parcel of making good predictions. However, more significant is the data being sent to the model and this is the point where domain expertise steps in. For instance, following the aforementioned example, the person who understands automotive sales may be better able to tell what affects the sale. Therefore, sending those particular variables as input will offer better predictions.
Unsupervised Learning
This type implies that there is no defined target in the data, and our focus is to explore the distribution of the data set. Clustering is one of the major use cases of unsupervised learning.
Clustering
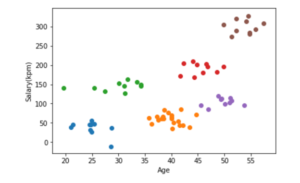
It identifies the clusters within the given set of data. For instance, there is a bank having data on customers’ salaries and ages. The management is willing to group up similar users to create product and marketing strategies around the developed groups.
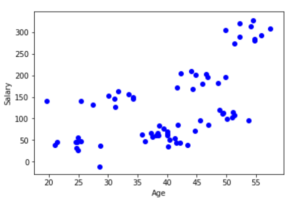
Note: Do not confuse salary being the target. The task here is not to predict the salaries of the employees from the data of their ages, but only to predict the people of similar salaries and age in groups. For this example, only these two variables were considered to easily illustrate the example. It made it possible to explore the data visually and make clusters without developing an algorithm. However, in real cases, multiple variables are there.
Each customer (data point) is now associated with a cluster denoted by certain color facilitating the development of strategies. The clustering algorithm may give us the following outcomes.
Other ML Algorithms
Apart from clustering unsupervised learning algorithms, for instance, dimensionality reduction. Since those have limited usage restricted to certain business cases, they overlook and may not be discussed in detail. However, these are mostly used to improve the performance of models.
Reinforcement learning
These ML algorithms are used to decide what should be done to maximize the rewards in long term in a lesser dynamic environment.
To conclude, you need to understand the nitty-gritty of ML to ensure the combination of the perfect algorithms with the right tools to gain maximum value. The deployment of ML in business processes, across different industries is proving to be extremely useful.
Related Posts
 10 Mind-Blowing AI Tools Everyone Should Be Trying Out Now
10 Mind-Blowing AI Tools Everyone Should Be Trying Out Now Technology Evolution: Top Tools and Trends Shaping 2024
Technology Evolution: Top Tools and Trends Shaping 2024 Want to Become a Successful Entrepreneur? Timing is Everything
Want to Become a Successful Entrepreneur? Timing is Everything Azure Logic Apps: Top 5 use cases and the road ahead of Microsoft integration
Azure Logic Apps: Top 5 use cases and the road ahead of Microsoft integration New Features In Logic Apps
New Features In Logic Apps Hype or Reality: Assessing the Impact of Generative AI on Businesses
Hype or Reality: Assessing the Impact of Generative AI on Businesses